Training the classifier
Discriminant Function Training is controlled from the Detection / Whistle Classifier / Discriminant Function Training … menu.
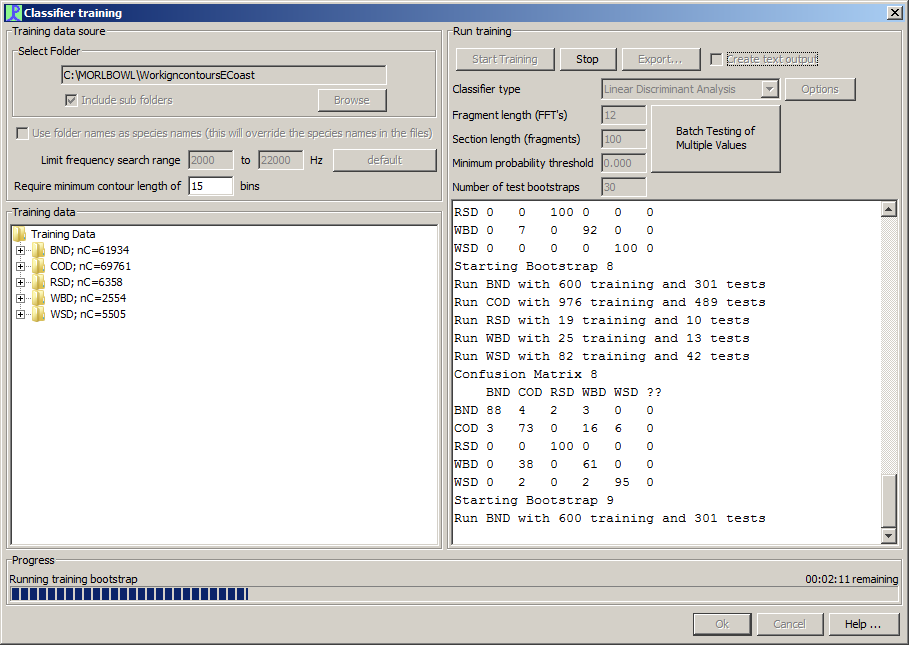
Training Data
Before running the training algorithms, you must process raw audio files for each species to create a training data set as described in the Collecting Training Data section. Training data will be in the form of a number of .wctd files containing extracted whistle contours from the Whistle and Moan detector
Select the file folder containing your .wctd files. The files can all be in the same folder or can be split into sub folders, in which case you should check the “Select Sub folders” option.
Limit Frequency Search Range - The frequency range to use. Contours outside this range will be discarded.
This is useful if there is low or high frequency noise in the system which you wish to exclude from the training process.
You can also require the classifier to only use whistle contours over a certain number of FFT bins long. Again, this can be useful if there are short bits of noise in the training data sample.
species names
When the wctd files were created, the species name (either input by the user of taken from the folder name of the source audio file) was written into each file. Species names from the .wctd files are used by default during the classifier training. However, it is possible to override the species names in the .wctd files by organising you .wctd files into sub folders with different names and selecting the “Use folder names as species names” option.
This allows you to merge data sets which may have been given slightly different names by different analyst (for instance, different people may have labelled training data for Bottlenose dolphin as “BND”, “Bottlenose”, “TT”, “Tursiops”, etc. It also allows you to merge species into groups, for instance, you might have a new “Small dolphin” category containing data for both common and striped dolphin.
Run Training
To run the training, set the following parameters:
Classifier Type - Two discriminant functions are available, Linear Discriminant Analysis and a Mahalanobis Distances Classifier.
Fragment Length - How long the fragments of whistle fed into the classifier should be.
Section length - how many fragments to accumulate before extracting parameters from the distribution and running a classification.
Minimum probability threshold - sets a minimum probability threshold for classification. If the classifier probability for the best class falls below this threshold, then the whistle section is marked as unclassified.
Number of test bootstraps - The number of randomised trials to run when testing classifier performance
Batch Testing of Multiple Values - This button will open an additional dialog which allows you to enter a range of values for the fragment length, section length and probability threshold. The bootstrap is then carried out for each set of parameters and the output dumped to a text file. Examination of the text file help to decide on the optimum values for these parameters.
Press the “Start Training” button and wait while the classifier training process runs.
Progress will be indicated in the bar at the bottom of the window and also as text output in the right hand display panel.
Training Output
The training process produces a number of matrices which will control the classification process. These are automatically stored into the standard PAMGuard settings file you are currently using.
You can also export the classifier settings to a Whistle Classifier Settings (*.wcsd) file for archiving and easy sharing with other users so that they can set up the same classifier without requiring access to the training data set.